
Background
Recently, in my senior project, we have been doing a lot of modeling in R. We are somewhat limited to running code on our own machines (instead of leveraging cloud resources), so there has been a fair amount of waiting for code to finish running. Not a crazy amount, but still. Training algorithms and tuning hyperparameters (the parameters that are not necessarily learned directly from the data, like what K to choose in K nearest neighbors), can often be a huge burden on less powerful machines. That means these computations take time. This post is an attempt to help you deal with that reality.
Five tips / resources
Hopefully I don’t annoy you with repeating the term “computationally expensive operations” too much. Below I have listed the five main points that we will discuss in this post.
tictocpackage - timing computationally expensive operationsbeeprpackage - play a notification sound after computationally expensive operations finish runningpinspackage - cache computationally expensive operations for sharing and future re-use- parallel processing - use multiple cores or separate machines to split up the burden of computationally expensive operations
- R jobs in RStudio - run computationally expensive operations in the background using local jobs
We will demonstrate the use of these resources using a simple machine learning example. As always, here are the packages that you will need to install and load in order to run the code yourself:
# install.packages(c('pins', 'tictoc', 'beepr', 'doParallel', 'tidymodels'))
library(tidymodels) # modeling that follows the tidyverse design philosophy
library(pins) # cache computations and share data easily
library(tictoc) # time how long code takes to run
library(beepr) # play sound
Setting up the example
For our example we will set up a basic decision tree regressor with the tidymodels suite of R packages. tidymodels is to modeling as the tidyverse is to data wrangling and visualization. They are both meta-packages that house many smaller packages that work well together and share a common API and design philosophy.
If you have ever used the popular caret package to do modeling in R, tidymodels is sort of like the successor to caret. The fantastic caret author, Max Kuhn, is leading the tidymodels team at RStudio. This post is not really meant to be an introduction to tidymodels, but the API is straightforward enough that the example should make sense without too much explanation. I’ll link to resources for learning more at the end of the post, and I may do an “Intro to tidymodels” type post in the future. I mostly want to focus on the five tips mentioned previously.
The data that we will use is from the diamonds dataset in the ggplot2 package. It contains price and other attributes of over 50,000 diamonds. Also, the tidymodels meta-package contains ggplot2 and dplyr for all your data wrangling and visualization needs, so there is generally no need to load them separately.
# ?diamonds - run this in your console to
# learn more about the diamonds dataset
dat <- ggplot2::diamonds
glimpse(dat)
Rows: 53,940
Columns: 10
$ carat <dbl> 0.23, 0.21, 0.23, 0.29, 0.31, 0.24, 0.24, 0.26, 0.22~
$ cut <ord> Ideal, Premium, Good, Premium, Good, Very Good, Very~
$ color <ord> E, E, E, I, J, J, I, H, E, H, J, J, F, J, E, E, I, J~
$ clarity <ord> SI2, SI1, VS1, VS2, SI2, VVS2, VVS1, SI1, VS2, VS1, ~
$ depth <dbl> 61.5, 59.8, 56.9, 62.4, 63.3, 62.8, 62.3, 61.9, 65.1~
$ table <dbl> 55, 61, 65, 58, 58, 57, 57, 55, 61, 61, 55, 56, 61, ~
$ price <int> 326, 326, 327, 334, 335, 336, 336, 337, 337, 338, 33~
$ x <dbl> 3.95, 3.89, 4.05, 4.20, 4.34, 3.94, 3.95, 4.07, 3.87~
$ y <dbl> 3.98, 3.84, 4.07, 4.23, 4.35, 3.96, 3.98, 4.11, 3.78~
$ z <dbl> 2.43, 2.31, 2.31, 2.63, 2.75, 2.48, 2.47, 2.53, 2.49~Let’s says after doing some initial exploration of the data that we want to try and predict price using the rest of the columns (variables/features) in our data.
# quick plot from gglot2 to see the
# distribution of diamond prices
ggplot2::qplot(data = dat, x = price, bins = 100) +
labs(title = "Most diamonds aren't crazy expensive")

First, we will split our data into training and testing sets using functions from tidymodels.
# initial_split, training, and testing
# are functions from the rsample
# package that is part of tidymodels
# set a seed for reproducibility
set.seed(123)
# split the data, using 3/4 for training
# and 1/4 for testing
dat_split <- initial_split(data = dat, prop = 3/4)
# get the training and testing sets from the data split
dat_train <- training(dat_split)
dat_test <- testing(dat_split)
# again, I won't go into the tidymodels stuff too much,
# but dat_split is an rsample rsplit object.
dat_split
<Analysis/Assess/Total>
<40455/13485/53940>dat_train
# A tibble: 40,455 x 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
3 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
4 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
5 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53
6 0.22 Fair E VS2 65.1 61 337 3.87 3.78 2.49
7 0.3 Good J SI1 64 55 339 4.25 4.28 2.73
8 0.23 Ideal J VS1 62.8 56 340 3.93 3.9 2.46
9 0.22 Premium F SI1 60.4 61 342 3.88 3.84 2.33
10 0.31 Ideal J SI2 62.2 54 344 4.35 4.37 2.71
# ... with 40,445 more rowsdat_test
# A tibble: 13,485 x 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
2 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
3 0.24 Very Good I VVS1 62.3 57 336 3.95 3.98 2.47
4 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39
5 0.32 Premium E I1 60.9 58 345 4.38 4.42 2.68
6 0.3 Ideal I SI2 62 54 348 4.31 4.34 2.68
7 0.3 Good J SI1 63.4 54 351 4.23 4.29 2.7
8 0.3 Good J SI1 63.8 56 351 4.23 4.26 2.71
9 0.3 Very Good J VS2 62.2 57 357 4.28 4.3 2.67
10 0.23 Very Good F VS1 60.9 57 357 3.96 3.99 2.42
# ... with 13,475 more rowsNext we will further split dat_train, our training set, so that later on we can use cross-validation to find the best hyperparameters for our decision tree.
set.seed(123)
#rsample::vfold_cv for creating cross-validation folds
folds <- vfold_cv(dat_train, v = 5) # v = 10 is the default
folds
# 5-fold cross-validation
# A tibble: 5 x 2
splits id
<list> <chr>
1 <split [32364/8091]> Fold1
2 <split [32364/8091]> Fold2
3 <split [32364/8091]> Fold3
4 <split [32364/8091]> Fold4
5 <split [32364/8091]> Fold5Now we will create something called a model specification, and we will mark the decision tree hyperparameters, tree_depth and cost_complexity, that we want to tune with the special placeholder function, tune(). tree_depth is simply the maximum depth of the tree, while cost_complexity will hopefully help to create a simpler tree that doesn’t overfit the training data. At this point we haven’t fit any data to the model, but instead we are basically laying out a blueprint for our model.
# tidymodels uses the parsnip package for creating
# model specifications like decision_tree()
tree_spec <- decision_tree(
cost_complexity = tune(), # mark that we will be tuning cost_complexity
tree_depth = tune() # mark that we will be tuning tree_depth
) %>%
# specify the computational engine for the decision tree,
# in this case we will use an algorithm from the
# rpart R package
set_engine('rpart') %>%
# specify that we want our decision tree to do
# regression, instead of the default classification
set_mode('regression')
At this point, we can also create a grid of candidate hyperparameters with which to tune our decision tree. We can use this grid to train many models using our cross-validation folds and see which models turn out best with specific hyperparameters.
tree_grid <- grid_regular(
cost_complexity(),
tree_depth(),
levels = 3 # realistically you would want a lot more than 3 levels
)
tree_grid
# A tibble: 9 x 2
cost_complexity tree_depth
<dbl> <int>
1 0.0000000001 1
2 0.00000316 1
3 0.1 1
4 0.0000000001 8
5 0.00000316 8
6 0.1 8
7 0.0000000001 15
8 0.00000316 15
9 0.1 15Almost done setting up the example, I swear. Maybe I should have turned this into a tidymodels tutorial. Anyways, tidymodels contains the workflows package that allows you to bundle together models, formulas, and pre-processing recipes (which we haven’t shown in this post). This makes it easy to work with just a single object instead of multiple objects scattered across an analysis.
tree_workflow <- workflow() %>%
add_model(tree_spec) %>%
add_formula(price ~ .)
tree_workflow
== Workflow ==========================================================
Preprocessor: Formula
Model: decision_tree()
-- Preprocessor ------------------------------------------------------
price ~ .
-- Model -------------------------------------------------------------
Decision Tree Model Specification (regression)
Main Arguments:
cost_complexity = tune()
tree_depth = tune()
Computational engine: rpart tictoc and beepr
Finally, we will tune the hyperparameters using tune_grid and the objects that we have created previously. tune_grid will fit a model for each combination of fold and hyperparameter set. In this case, 45 models will be trained. The performance for each parameter set is averaged across the folds, so that you will be able to see the average performance for 9 different sets of hyperparameters. Hopefully that makes sense.
[1] 45Depending on how much data you have or how many hyperparameters you are trying, tuning may take a long time. I have found it super helpful to take note of how long operations take, just in case I need to run code again.
We will use tic and toc from the tictoc package to time how long our code takes to run. Put tic before the code you want to time, and toc at the end. Either run the whole chunk at once (if using rmarkdown) or highlight all of the code and run it at once (if in a script). Also, the msg is optional. I usually don’t worry about it.
We can also include beepr::beep after toc to play a specific notification sound for when the code finishes running. You could start your code, go make a sandwich, and then hear when it is done.
tic(msg = 'tuning decision tree hyperparameters')
tune_results <- tune_grid(
tree_workflow, # bundle of model and formula
resamples = folds, # cross-validation folds
grid = tree_grid # grid of hyperparameter candidates
)
toc()
tuning decision tree hyperparameters: 39.44 sec elapsedbeep('fanfare')
Here are the results:
tune_results
# Tuning results
# 5-fold cross-validation
# A tibble: 5 x 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [32364/8091]> Fold1 <tibble [18 x 6]> <tibble [0 x 1]>
2 <split [32364/8091]> Fold2 <tibble [18 x 6]> <tibble [0 x 1]>
3 <split [32364/8091]> Fold3 <tibble [18 x 6]> <tibble [0 x 1]>
4 <split [32364/8091]> Fold4 <tibble [18 x 6]> <tibble [0 x 1]>
5 <split [32364/8091]> Fold5 <tibble [18 x 6]> <tibble [0 x 1]>There are various convenience functions that help you access the resulting data without having to use tidyr or purrr.
Collect the performance metrics from the models.
tune_results %>% collect_metrics()
# A tibble: 18 x 8
cost_complexity tree_depth .metric .estimator mean n std_err
<dbl> <int> <chr> <chr> <dbl> <int> <dbl>
1 0.0000000001 1 rmse standard 2.49e+3 5 1.72e+1
2 0.0000000001 1 rsq standard 6.10e-1 5 2.65e-3
3 0.00000316 1 rmse standard 2.49e+3 5 1.72e+1
4 0.00000316 1 rsq standard 6.10e-1 5 2.65e-3
5 0.1 1 rmse standard 2.49e+3 5 1.72e+1
6 0.1 1 rsq standard 6.10e-1 5 2.65e-3
7 0.0000000001 8 rmse standard 7.16e+2 5 5.99e+0
8 0.0000000001 8 rsq standard 9.68e-1 5 8.90e-4
9 0.00000316 8 rmse standard 7.16e+2 5 6.01e+0
10 0.00000316 8 rsq standard 9.68e-1 5 8.92e-4
11 0.1 8 rmse standard 1.81e+3 5 1.24e+1
12 0.1 8 rsq standard 7.94e-1 5 3.57e-3
13 0.0000000001 15 rmse standard 6.37e+2 5 6.70e+0
14 0.0000000001 15 rsq standard 9.75e-1 5 7.56e-4
15 0.00000316 15 rmse standard 6.41e+2 5 6.79e+0
16 0.00000316 15 rsq standard 9.74e-1 5 7.81e-4
17 0.1 15 rmse standard 1.81e+3 5 1.24e+1
18 0.1 15 rsq standard 7.94e-1 5 3.57e-3
# ... with 1 more variable: .config <chr>Show just the best results for a specific performance metric.
tune_results %>% show_best('rsq')
# A tibble: 5 x 8
cost_complexity tree_depth .metric .estimator mean n std_err
<dbl> <int> <chr> <chr> <dbl> <int> <dbl>
1 0.0000000001 15 rsq standard 0.975 5 0.000756
2 0.00000316 15 rsq standard 0.974 5 0.000781
3 0.0000000001 8 rsq standard 0.968 5 0.000890
4 0.00000316 8 rsq standard 0.968 5 0.000892
5 0.1 8 rsq standard 0.794 5 0.00357
# ... with 1 more variable: .config <chr>Anyways, check out the docs for more on tidymodels.
tic and toc are rather nifty. They can be nested if needed (from the documentation):
inner: 3.04 sec elapsed toc()
middle: 5.07 sec elapsedtoc()
outer: 6.11 sec elapsedbeep can use any of the ten options below for playing different sounds, and you can use either text or numbers.
- “ping”
- “coin”
- “fanfare”
- “complete”
- “treasure”
- “ready”
- “shotgun”
- “mario”
- “wilhelm”
- “facebook”
Fans of classic video games will appreciate these sounds:
beep(5)
beep('mario')
pins
It is very likely that you will not complete an entire analysis in one sitting. Having to re-run expensive computations is burdensome. To save time, I have found it very useful to pin certain computations using the pins package. pins makes it incredibly easy to cache and retrieve data.
To pin some data, first register a board to pin it on. In my normal R scripts, I’ll usually include the code below right after library(pins). If you don’t specify a name for your board, it will just default to local.
board_register_local(name = 'models')
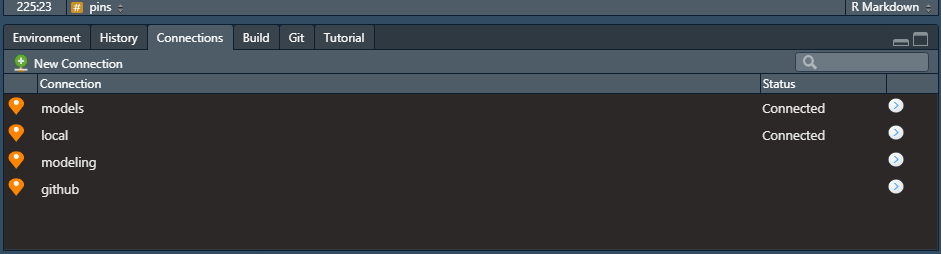
In the code above, we are just registering a local board. There are a plethora of options though, like registering boards on GitHub (board_register_github) or Azure (board_register_azure). If you are following along in RStudio, you should see something similar in your connections pane (I have more boards then just models):
Now that we registered a board, we can use pins::pin to pin our tune_results object to the models board. Notice that we use the base AsIs function, I, so that our tune_results object keeps all of its fancy R properties. We wouldn’t need this if we just wanted to save a csv file or something similar.
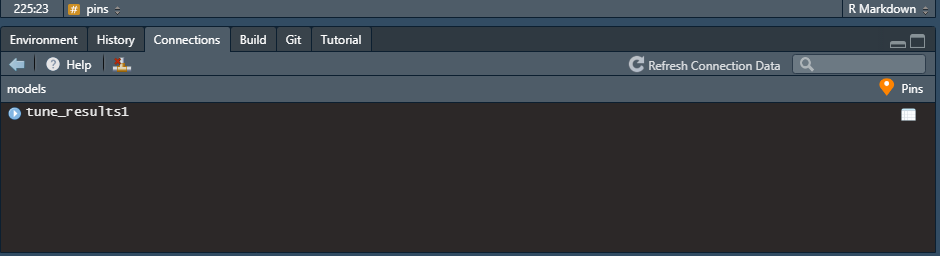
Once you pin tune_results1 to models, you should see something like this:
We could quit R and RStudio, and then we could come back later and retrieve our pinned object with pin_get. We would not have to re-run tune_grid (we would still want to load libraries and perhaps other code). This could save many minutes or hours of waiting around for code to finish running, depending on what you are doing.
pin_get(name = 'tune_results1', board = 'models')
# Tuning results
# 5-fold cross-validation
# A tibble: 5 x 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [32364/8091]> Fold1 <tibble [18 x 6]> <tibble [0 x 1]>
2 <split [32364/8091]> Fold2 <tibble [18 x 6]> <tibble [0 x 1]>
3 <split [32364/8091]> Fold3 <tibble [18 x 6]> <tibble [0 x 1]>
4 <split [32364/8091]> Fold4 <tibble [18 x 6]> <tibble [0 x 1]>
5 <split [32364/8091]> Fold5 <tibble [18 x 6]> <tibble [0 x 1]>When pinning an object and coming back to an analysis later, I will often comment out the expensive computation, and instead just retrieve my desired data with pin_get, assigning that data to the same variable. For example:
# tic(msg = 'tuning decision tree hyperparameters')
# tune_results <- tune_grid(
# tree_workflow, # bundle of model and formula
# resamples = folds, # cross-validation folds
# grid = tree_grid # grid of hyperparameter candidates
# )
# toc()
# beep('fanfare')
#
# pin(I(tune_results), name = 'tune_results1', board = 'models')
tune_results <- pin_get(name = 'tune_results1', board = 'models')
Here we see the object is the same. We could then just pick up where we left off without having to run the code again.
tune_results
# Tuning results
# 5-fold cross-validation
# A tibble: 5 x 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [32364/8091]> Fold1 <tibble [18 x 6]> <tibble [0 x 1]>
2 <split [32364/8091]> Fold2 <tibble [18 x 6]> <tibble [0 x 1]>
3 <split [32364/8091]> Fold3 <tibble [18 x 6]> <tibble [0 x 1]>
4 <split [32364/8091]> Fold4 <tibble [18 x 6]> <tibble [0 x 1]>
5 <split [32364/8091]> Fold5 <tibble [18 x 6]> <tibble [0 x 1]>If working in an Rmarkdown file, you could also just set the chunk with the expensive computation to eval = FALSE.
parallel processing
It can also be useful to speed up computations by splitting up the work across multiple cores on your computer. You can do this with the following code.
num_cores <- parallel::detectCores() - 1 # use all but one core
cl <- parallel::makePSOCKcluster(num_cores)
doParallel::registerDoParallel(cl)
The code above sets you up for parallel processing. tune is smart enough to just work; it defaults to allowing for parallel processing.
tic(msg = 'tuning decision tree hyperparameters')
tune_results2 <- tune_grid(
tree_workflow, # bundle of model and formula
resamples = folds, # cross-validation folds
grid = tree_grid # grid of hyperparameter candidates
)
toc()
tuning decision tree hyperparameters: 33.94 sec elapsedbeep('fanfare')
tune_results2
# Tuning results
# 5-fold cross-validation
# A tibble: 5 x 4
splits id .metrics .notes
<list> <chr> <list> <list>
1 <split [32364/8091]> Fold1 <tibble [18 x 6]> <tibble [0 x 1]>
2 <split [32364/8091]> Fold2 <tibble [18 x 6]> <tibble [0 x 1]>
3 <split [32364/8091]> Fold3 <tibble [18 x 6]> <tibble [0 x 1]>
4 <split [32364/8091]> Fold4 <tibble [18 x 6]> <tibble [0 x 1]>
5 <split [32364/8091]> Fold5 <tibble [18 x 6]> <tibble [0 x 1]>According to the docs, there are also other packages that you can use, like doFuture.
Outside of the world of tidymodels, there are other packages that I would recommend for parallel processing. Checkout the furrr package for parallel processing with future and purrr. For parallel processing with dplyr, look into the excellent multidplyr package.
R jobs
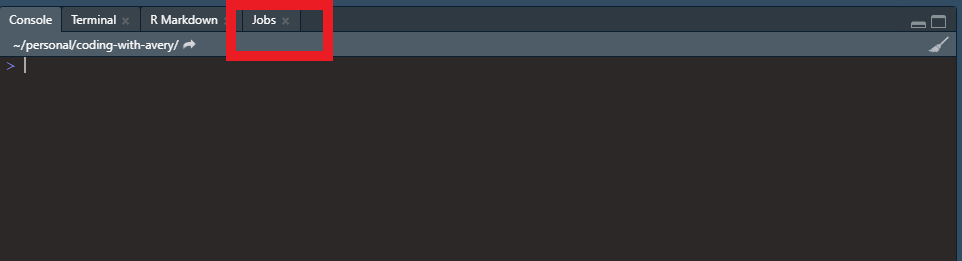
Last, but not least, we should talk about R jobs in RStudio. With jobs, you can run R scripts in the background and continue to use R and RStudio for other work. Depending on how you have your panes set up in RStudio, you should see something like the following somewhere in your IDE:
Click on the jobs tab and you will see this:
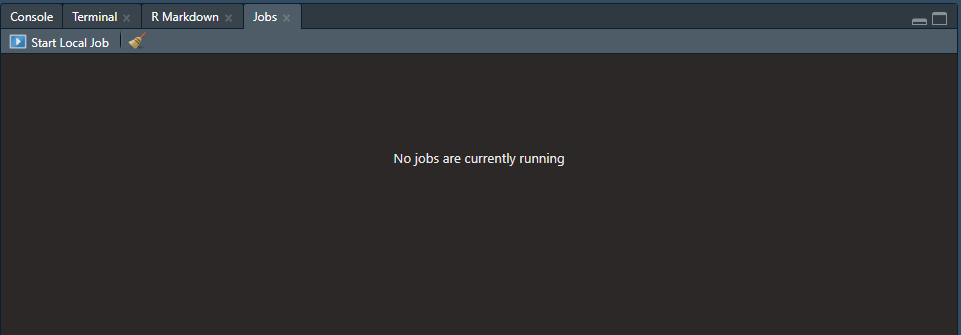
Then click Start Local Job.
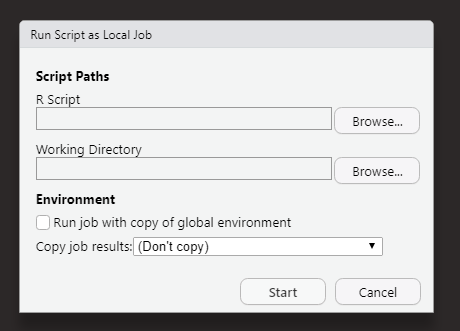
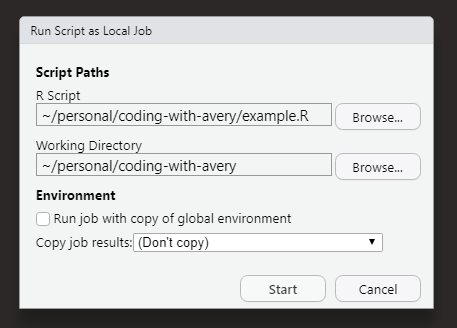
You can then specify what script you want to run as a local job. You can also specify the working directory that you want for the script, which can be important for file paths and reading in data, etc. You will also want to decided whether or not you want the job to run with a copy of the global environment or not, and what you want to do with the results. If you are using pins in your script, those objects will get pinned to their respective boards.
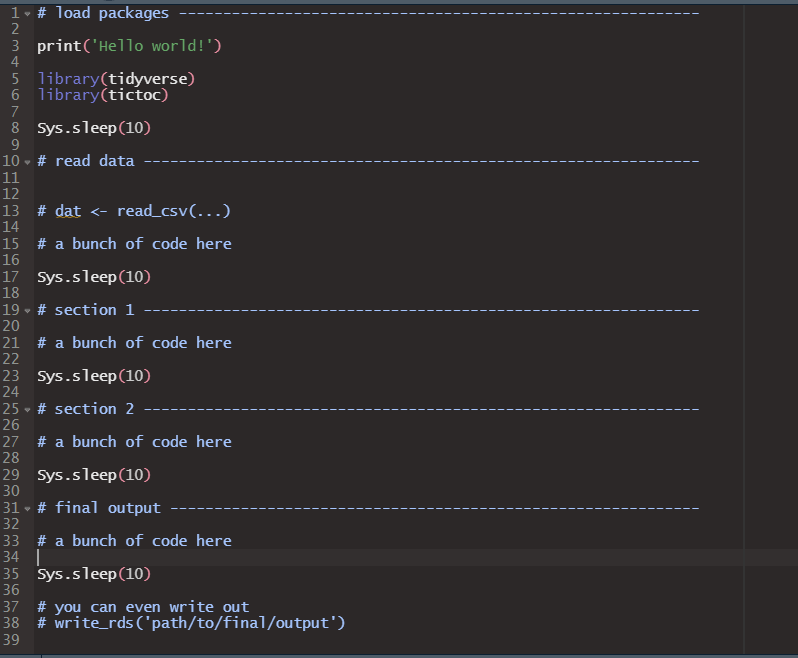
If you insert sections in your script, like seen below, then those section titles will show up above the progress bar of the currently running job. The shortcut, at least on Windows, to insert these sections in an R script is ctrl + shift + R. Maybe a Mac user can confirm in the comments if that is the same or not.
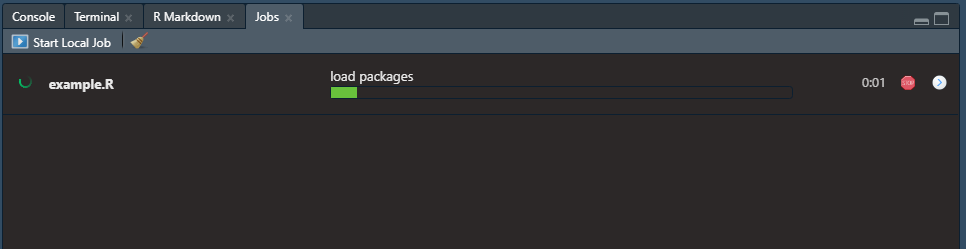
Then the progress of your job can be seen as follows:
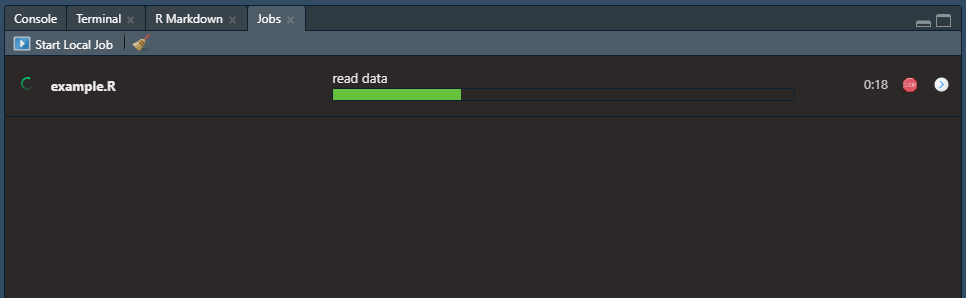
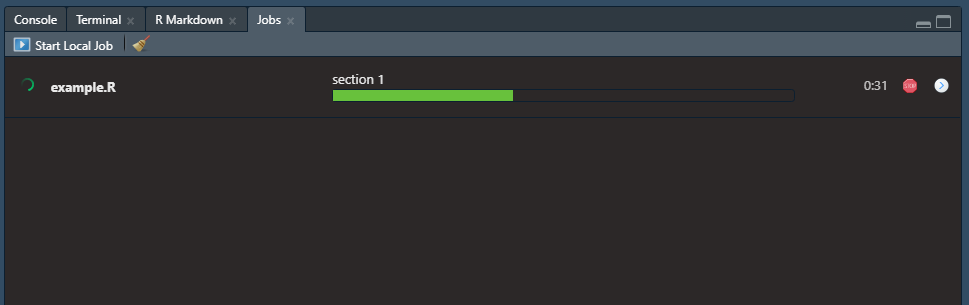
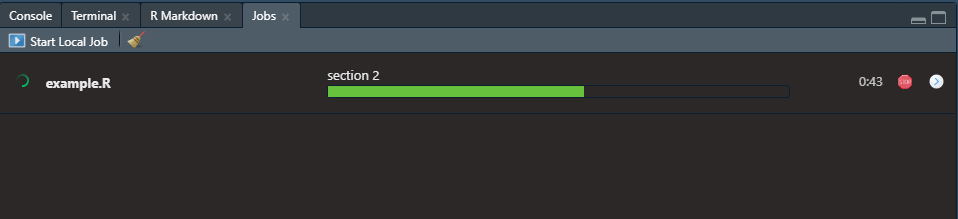
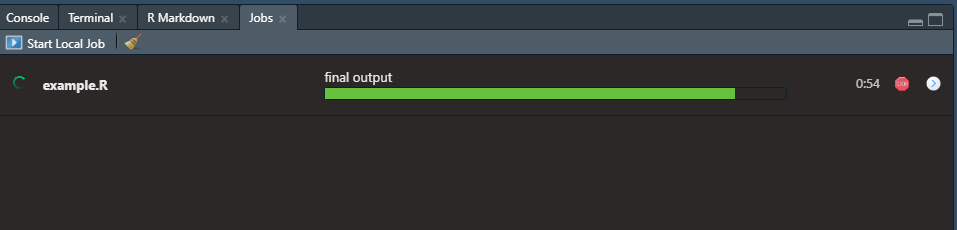
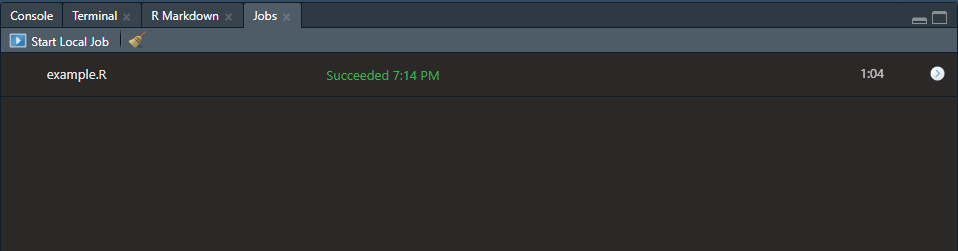
For a more comprehensive look at Jobs, see here.
Might as well finish the tidymodels example
I did not really mean to set out to explain as much of the tidymodels stuff as I did, but because I said what I said I might as well finish the example. If I wanted to fit the model with the best r-squared to all of the training data and test on the testing data, I would do the following.
First, select the model with the best performing hyperparamters.
best_params <- tune_results %>% select_best('rsq')
best_params
# A tibble: 1 x 3
cost_complexity tree_depth .config
<dbl> <int> <chr>
1 0.0000000001 15 Preprocessor1_Model7Second, update or finalize your existing workflow so that the tune placeholders are replaced with the actual values of the hyperparameters.
# original workflow
tree_workflow
== Workflow ==========================================================
Preprocessor: Formula
Model: decision_tree()
-- Preprocessor ------------------------------------------------------
price ~ .
-- Model -------------------------------------------------------------
Decision Tree Model Specification (regression)
Main Arguments:
cost_complexity = tune()
tree_depth = tune()
Computational engine: rpart # finalized workflow
final_workflow <- tree_workflow %>%
finalize_workflow(best_params)
final_workflow
== Workflow ==========================================================
Preprocessor: Formula
Model: decision_tree()
-- Preprocessor ------------------------------------------------------
price ~ .
-- Model -------------------------------------------------------------
Decision Tree Model Specification (regression)
Main Arguments:
cost_complexity = 1e-10
tree_depth = 15
Computational engine: rpart Third, use the last_fit function to train the final workflow/model on the entire training set and validate using the entire testing set. Remember that these two sets are within the dat_split object.
final_fit <- last_fit(final_workflow, dat_split)
final_fit
# Resampling results
# Manual resampling
# A tibble: 1 x 6
splits id .metrics .notes .predictions .workflow
<list> <chr> <list> <list> <list> <list>
1 <split [40~ train/te~ <tibble [2~ <tibble ~ <tibble [13,4~ <workflo~How did our final model do? Let’s check the metrics.
final_fit %>% collect_metrics()
# A tibble: 2 x 4
.metric .estimator .estimate .config
<chr> <chr> <dbl> <chr>
1 rmse standard 598. Preprocessor1_Model1
2 rsq standard 0.977 Preprocessor1_Model1Pretty awesome. Our final r-squared value was almost exactly the same as the previous r-squared that we looked at, suggesting that our decision tree regressor did not really overfit the data. In other words, the model seems to be generalizing fairly well on data that it has not seen before. Furthermore, the decision tree model explains about 97% of the variability in our response variable, diamond price.
dat_pred <- final_fit %>% collect_predictions()
head(dat_pred, 5)
# A tibble: 5 x 5
id .pred .row price .config
<chr> <dbl> <int> <int> <chr>
1 train/test split 357. 2 326 Preprocessor1_Model1
2 train/test split 485. 5 335 Preprocessor1_Model1
3 train/test split 448. 7 336 Preprocessor1_Model1
4 train/test split 426. 10 338 Preprocessor1_Model1
5 train/test split 456. 16 345 Preprocessor1_Model1Let’s plot the actual values against the predicted values real quick to see visually how our model did.
dat_pred %>%
ggplot() +
geom_point(aes(x = price, y = .pred),
alpha = 0.25, color = 'navy') +
theme_minimal() +
labs(title = 'Decision tree does a good job at predicting diamond price')

Again, not bad.
The last thing we might do is train the model one last time on all of the data that we have. We could then save this model and use it in a shiny app or create a plumber API to use the model elsewhere.
final_model <- fit(final_workflow, dat)
# write_rds(final_model, 'path/to/wherever/you/want.rds')
Recap
We looked at the tictoc package for timing computations in R. We also had fun with the beepr package for playing notification sounds. We now know how to cache data and expensive computations with pins. By the way, pins is also available in corresponding packages in JavaScript and Python, allowing for cross-language collaboration. Lastly, we touched on parallel processing with R and how to run R scripts in the background with local jobs. Hopefully all of these tips and resources will help you when working with computationally expensive code in R.
Learning more about tidymodels
The tidymodels website has an amazing set of getting started tutorials to look into if you are new to tidymodels.
Farewell
Thank you for reading! I truly hope you found something of use here. Stay safe and happy coding!
R and package versions
R.version
_
platform x86_64-w64-mingw32
arch x86_64
os mingw32
system x86_64, mingw32
status
major 4
minor 0.3
year 2020
month 10
day 10
svn rev 79318
language R
version.string R version 4.0.3 (2020-10-10)
nickname Bunny-Wunnies Freak Out packageVersion('tidymodels')
[1] '0.1.2'packageVersion('pins')
[1] '0.4.5'packageVersion('tictoc')
[1] '1.0'packageVersion('beepr')
[1] '1.3'packageVersion('doParallel')
[1] '1.0.16'